preface
python 的主要应用领域:
- 数据科学、数据分析
- 爬虫
- 自动化运维
- 脚本
- 机器学习
本文,是关于 python 爬虫方向的知识整理。
爬取网站: https://huaban.com/favorite/beauty
参考教程:
一、过程
1.1 第一个问题
关于爬到的html与f12得到的有区别,所以re写
pattern不能凭着F12
目标:找到一个合适的pattern便于找到url
所谓查看网页源代码,就是别人服务器发送到浏览器的原封不动的代码。这是爬虫获得的代码
你那些在源码中找不到的代码(元素),那是在浏览器执行js动态生成的,这些能在审查元素中看到
通过审查元素就,看到就是浏览器处理过的最终的html代码。
然后试了试更换头信息,
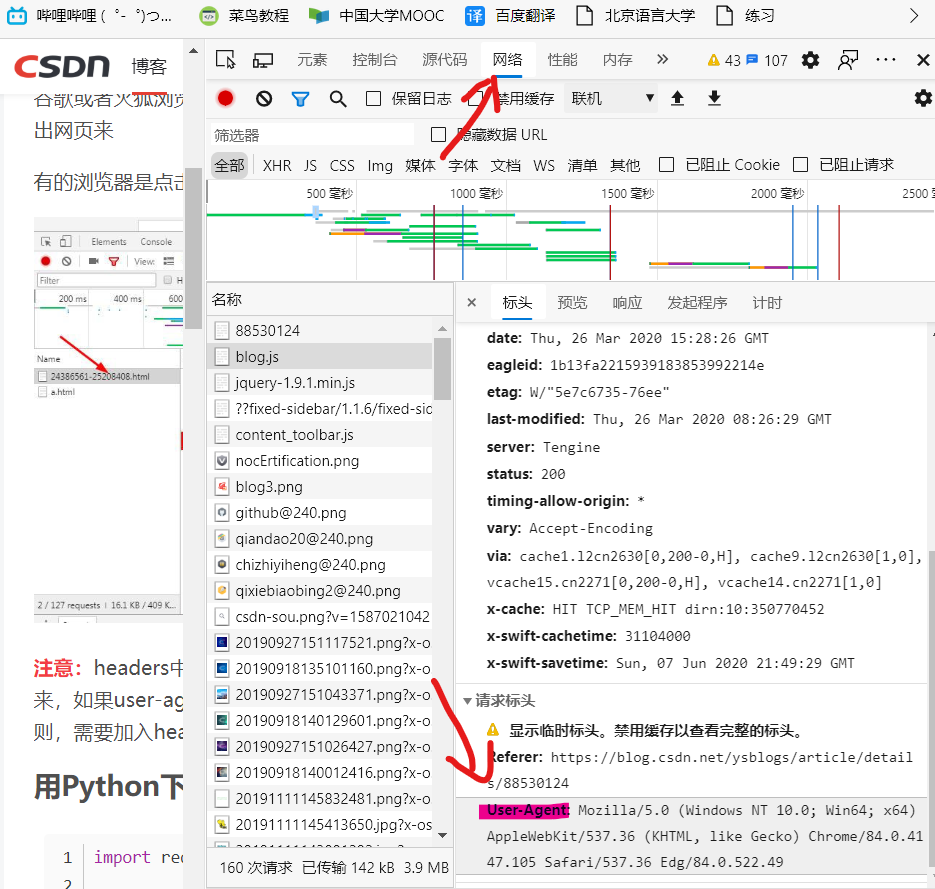
就离谱,requests.get过来的基本没找到
<div>标签,F12检查元素全是<div>标签
感觉:爬到的和F12到的是两个东西
1.2 第二个问题
从得到的text中找出图片的地址
先用 http://www.bejson.com/ 进行text分析,发现图片的地址为https://hbimg.huabanimg.com/+key
1.3 第三个问题
关于得到数据的不完整性,
目标:找出url_next
爬到的东西只有前面一些图片,经查询好像是一种关于动态网页异步更新的技术
参考: https://zhuanlan.zhihu.com/p/27346009
(当然网站表面没有页,表面的url也没有变)
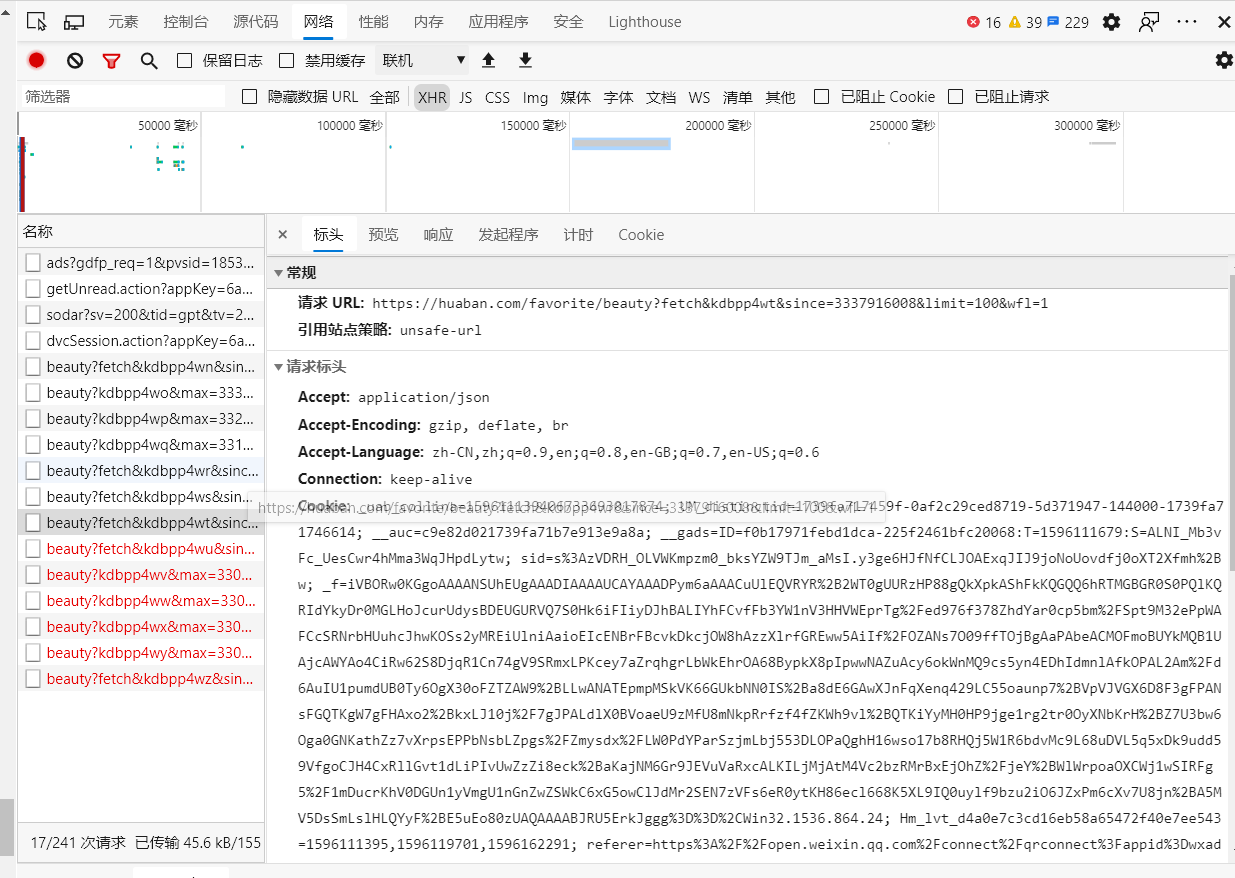
经查询,向下翻页时XHR会多出请求,url地址已给出
是时候更改1.0版本的代码,让它找到更多的图片🎈(自动加载新页)
经过第一个问题的折磨,容易理解:
- 虽然(翻页后的)url,用浏览器无法访问,但get可以爬到
二、基础知识
2.1 关于requests
开始使用第一步:
import requests
r=requests.get("http://")
r.status_code #en,返回200表示成功
开始使用第二步:
r.encoding = 'utf-8'
r.text #en,返回网站的html
其它:
r.apparent_encoding 【从内容分析出响应内容编码方式,返回一个编码方式字符串】r.raise_for_status 【如果不是200,返回异常码】
七个主要方法:
requests.request(method,url,**kwargs)requests.get(url,**kwargs), headers中伪装头信息- requests.post()
- requests.put()
- requests.patch()
- requests.head()
- requests.delete()
2.2 关于re
https://www.unielu.com/posts/10df.html
2.3 关于面向对象
if __name__ == '__main__'
表示:只有当该文件作为一个独立的脚本运行时才会被调用。
换句话说,如果在其它文件中导入此文件,那么条件中的语句不被执行。
三、代码实现
1.0版本:
import re
import requests
import os
pwd="C:/temp/temp"
url = "https://huaban.com/favorite/beauty/" #这是你要爬取的页面url
url_img = "https://hbimg.huabanimg.com/" #这是它放图片的url前缀
num=0
#伪装头信息
head = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36 Edg/84.0.522.49'}
def download(file,url):
print("开始下载:",file,url)
try:
r = requests.get(url,stream=True)
with open(file, 'wb') as fd:
for chunk in r.iter_content():
fd.write(chunk)
except Exception as e:
print("下载失败了",e)
def main(url):
global num
print("*******************************************")
print("你的请求网址是:",url)
r=requests.get(url,headers=head)
pattern=re.compile('{"pin_id":(\d*?),.*?"key":"(.*?)",.*?"like_count":(\d*?),.*?"repin_count":(\d*?),.*?}',re.S)
pid=0
items=re.findall(pattern,r.text)
for item in items:
pid,key,like_cnt,repin_cnt=item
print("开始下载第{}张图片".format(num))
pic_url=url_img+key #图片的url地址
filename=pwd+str(pid)+".jpg" #文件保存的名字
if os.path.isfile(filename):
print("文件存在:",filename)
continue
download(filename,pic_url)
num+=1
if not os.path.exists(pwd):
os.makedirs(pwd)
main(url)
1.1版本
import re
import requests
import os
pwd="C:/temp/temp"
url = "http://huaban.com/favorite/beauty/"
url_img = "https://hbimg.huabanimg.com/"
url_next="https://huaban.com/favorite/beauty?kdbpp4xg&max="
num=0
#伪装头信息
head = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36 Edg/84.0.522.49'}
def download(file,url):
print("开始下载:",file,url)
try:
r = requests.get(url,stream=True)
with open(file, 'wb') as fd:
for chunk in r.iter_content():
fd.write(chunk)
except Exception as e:
print("下载失败了",e)
def main(url):
global num
print("*******************************************")
print("你的请求网址是:",url)
r=requests.get(url,headers=head)
pattern=re.compile('{"pin_id":(\d*?),.*?"key":"(.*?)",.*?"like_count":(\d*?),.*?"repin_count":(\d*?),.*?}',re.S)
pid=0
items=re.findall(pattern,r.text)
for item in items:
pid,key,like_cnt,repin_cnt=item
print("开始下载第{}张图片".format(num))
pic_url=url_img+key #图片的url地址
filename=pwd+str(pid)+".jpg" #文件保存的名字
if os.path.isfile(filename):
print("文件存在:",filename)
continue
download(filename,pic_url)
num+=1
main(url_next+pid+"&limit=100&wfl=1") #比1.0多出的地方,参考问题3
if not os.path.exists(pwd):
os.makedirs(pwd)
main(url)
2.0 版本
2021-08-13 更新:
1、使用类对爬虫部分进行重写
2、可以设置路径、数目
3、加入图形化界面
import re
import requests
import os
import tkinter as tk
import tkinter.messagebox
import time
class pc:
def __init__(self, pwd = "C:/temp/", num = 66):
self.pwd = pwd
self.num = num
self.cnt = 0
self.url_img = "https://hbimg.huabanimg.com/"
self.url_next="https://huaban.com/favorite/beauty?kdbpp4xg&max="
#伪装头信息
self.head = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36 Edg/84.0.522.49'}
if not os.path.exists(pwd):
os.makedirs(pwd)
def download(self, file, url):
self.cnt += 1
print("\n==============================================")
print("开始下载第{}张图片".format(self.cnt))
print("下载图片:{}".format(url))
print("保存为:{}".format(file))
try:
r = requests.get(url,stream=True)
with open(file, 'wb') as fd:
for chunk in r.iter_content():
fd.write(chunk)
except Exception as e:
print("下载失败了",e)
def main(self, url):
print("**********************************************")
print("你的请求网址是:",url)
r = requests.get(url, headers = self.head)
pattern = re.compile('{"pin_id":(\d*?),.*?"key":"(.*?)",.*?"like_count":(\d*?),.*?"repin_count":(\d*?),.*?}', re.S)
items = re.findall(pattern, r.text)
for item in items:
pid, key, like_cnt, repin_cnt = item
pic_url = self.url_img + key #图片的url地址
filename = self.pwd + str(pid) + ".jpg" #文件保存的名字
if os.path.isfile(filename):
print("文件存在:",filename)
continue
self.download(filename, pic_url)
if self.cnt == self.num:
print("下载完成")
return
self.main(self.url_next + pid + "&limit=100&wfl=1") #页面加载
if __name__ == "__main__":
url = "http://huaban.com/favorite/beauty/"
def begin():
t1 = time.time()
entry_pwd = pwd.get()
entry_num = int(num.get())
p = pc(entry_pwd,entry_num)
p.main(url)
t2 = time.time()
tk.messagebox.showinfo(title='提示', message='下载完成,耗时{:.2f}s'.format(t2-t1))
window = tk.Tk()
window.title("花瓣网爬虫工具V2.0")
window.geometry("500x309")
tk.Label(text="欢迎使用该爬虫工具。⭐", font=('Arial', 14)).place(x=150, y=20)
tk.Label(window, text = "图片地址:https://hbimg.huabanimg.com/", font=('Arial', 14)).place(x=70,y=80)
tk.Label(window, text = "保存路径:", font=('Arial', 14)).place(x=70,y=120)
tk.Label(window, text = "下载数目:", font=('Arial', 14)).place(x=70,y=160)
pwd = tk.StringVar()
pwd.set("c:/temp/")
tk.Entry(window, textvariable=pwd, font=('Arial', 14)).place(x=170,y=120)
num = tk.StringVar()
num.set("5")
tk.Entry(window, textvariable=num, font=('Arial', 14)).place(x=170,y=160)
tk.Button(window, text="开始下载", font=('Arial', 14), command = begin).place(x=200,y=210)
tk.Label(window,text="说明:点击开始下载后会出现卡顿,全部下载完成后才会弹窗。").pack(side="bottom")
tk.Label(window,text="Designed by 将心晴").pack(side="bottom")
window.mainloop()
四、小结
2020.8.1
啦啦啦, 1.1版本成功,激动ing
今天还试了试 beautifulsoup ,fiddler ,没领悟~
2021.8.13
写了 V2.0 版本

打包成一个可执行的 .exe 文件之后 11.9mb

